· Kareem Hamed Ibrahim · Architecture · 4 min read
Learning Microservices by Building an E-Commerce Platform in Go
A journey through distributed systems design, from API Gateway to microservices orchestration, all built from scratch in Go.

The Question That Started It All
Over the past weeks, I took on an e-commerce platform as a learning project in Go. Not to launch it. Not to scale it to millions. But to answer a single question:
How do distributed systems actually work?
Most tutorials show you REST endpoints. But real systems are about orchestration—how services talk, how they fail, how they stay reliable when complexity grows.
So I built one from the ground up.
The Architecture: Five Services, One Vision
The system consists of 5 independent microservices:
- API Gateway — The front door
- User Service — Identity and profiles
- Product Service — Catalog and inventory
- Cart Service — Session state, lightning-fast
- Order Service — The transaction layer
Each service is independent. Deployable on its own. Replaceable without breaking the others.
System Diagram
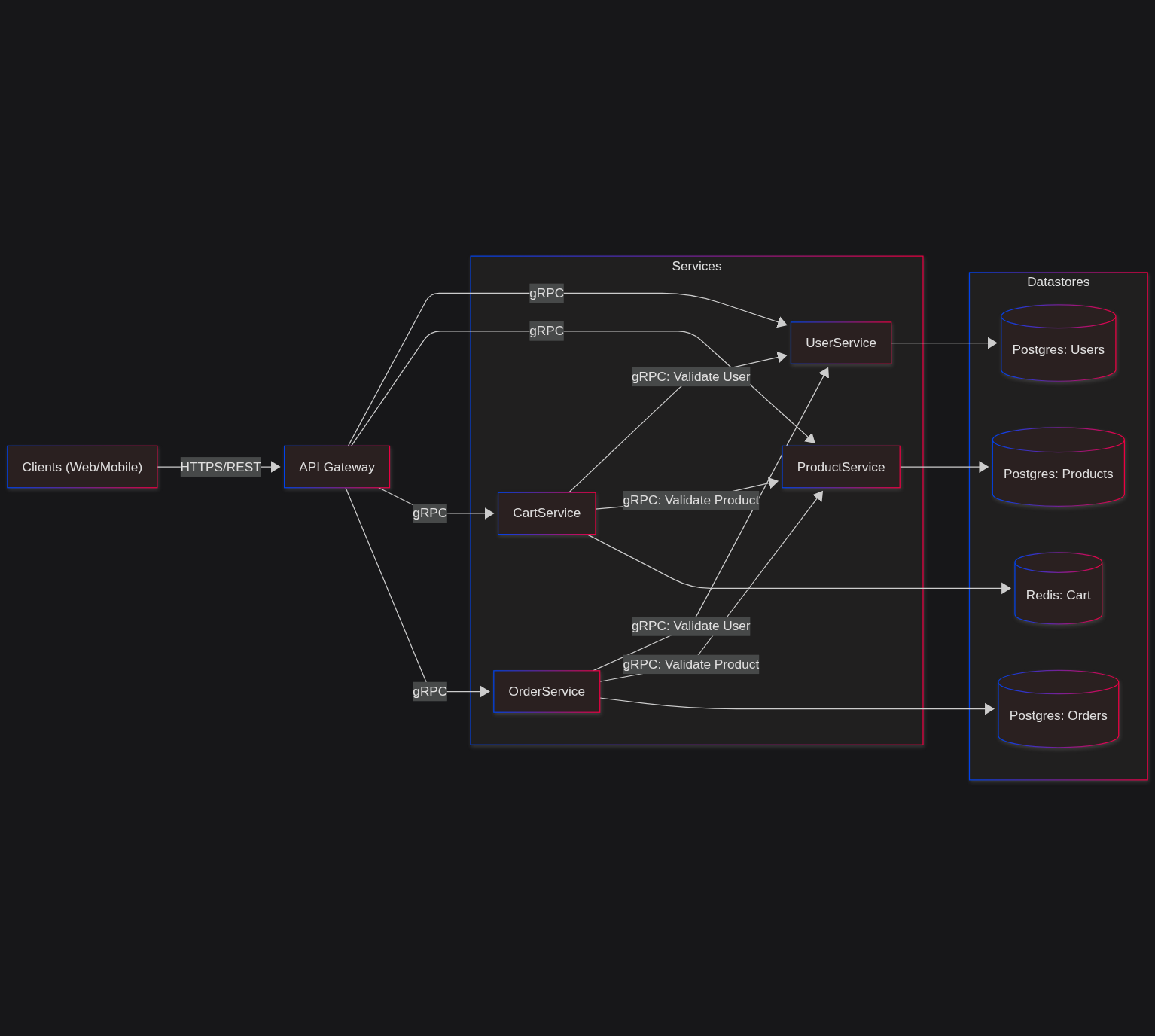
The diagram shows how clients communicate through the API Gateway, which routes requests to individual services (User, Product, Cart, Order). Services communicate with each other via gRPC for validation and data consistency. Each service has its own database (Postgres or Redis) following the database-per-service pattern.
The API Gateway: Control Flow
The API Gateway acts as a single entry point (Single Entry Point pattern). It’s responsible for:
- Authentication using JWT tokens
- Authorization with Role-Based Access Control (RBAC)
- Request routing to the appropriate service
- Rate limiting to protect backends
- Cross-cutting concerns like logging, tracing, and metrics
Without a gateway, every service would implement authentication separately. Bugs would multiply. The gateway centralizes this responsibility.
Inside Each Service: Clean Architecture
Every service follows the Clean Architecture pattern:
Domain → UseCase → Repository → DeliveryWhat does this buy you?
- Business logic lives in the Domain layer, untouched by framework details
- Use cases orchestrate the flow without caring about the database
- Repositories handle persistence as a detail, not a core concern
- Delivery layers (HTTP, gRPC) are just adapters
When your database needs to change? You swap the repository. When business rules shift? You modify use cases. The rest stays stable.
This separation makes testing easy and refactoring safe.
Data: Choosing the Right Persistence
Each service has its own database (Database per Service pattern):
- Postgres for User, Product, and Order services (strong consistency, ACID transactions)
- Redis for the Cart service (ultra-fast, in-memory state)
Why separate databases?
- Services don’t depend on each other’s schemas
- No shared database bottleneck
- Each service can scale independently
- Teams own their data models
The trade-off? Eventual consistency. If the product service updates price, the cart won’t reflect it instantly. But for an e-commerce flow, that’s acceptable and far more performant.
Communication: gRPC and Protocol Buffers
Services talk to each other using gRPC and Protocol Buffers, not REST.
Why?
- Contracts are explicit. A
.protofile defines exactly what parameters a service accepts and what it returns. No guessing. - Serialization is fast. Protocol Buffers are binary, much faster than JSON.
- Coupling is minimal. gRPC handles versioning gracefully.
Example flow:
- User submits a cart
- Cart Service calls User Service (via gRPC) to verify the user exists
- Cart Service calls Product Service (via gRPC) to validate product prices
- Order Service verifies everything before committing the order
Each call is explicit. Each failure is observable.
Reliability: Handling Failures Gracefully
Distributed systems will fail. The question is: how do you fail gracefully?
I implemented:
- Circuit Breaker Pattern: If User Service is down, Cart Service doesn’t keep hammering it. After a threshold of failures, the circuit opens, failing fast.
- Graceful Shutdown: When a service stops, it finishes in-flight requests before dying. No abrupt terminations.
Without these, a single failing service can cascade and bring down the entire system.
Observability: Seeing Into the System
You can’t fix what you can’t see.
I integrated:
- Distributed Tracing with OpenTelemetry: A single request travels through 5 services. Tracing lets me see the entire journey—where time is spent, where failures occur.
- Structured Logging: Instead of reading free-form logs, I log as JSON with context (user ID, request ID, service name). Analysis becomes data-driven.
When something breaks, you know exactly where.
Deployment: Docker and Orchestration
The entire system runs on Docker. Each service is a container. Easy to develop locally, easy to deploy to production.
The Real Learning
Building this taught me something critical:
Simple decisions compound.
When I chose to use separate databases, I was solving one problem. But it had ripple effects:
- How do I handle transactions across services? (Saga pattern)
- How do I maintain consistency? (Eventual consistency + compensation)
- How do I test this? (Different strategy than monoliths)
Each choice shaped the entire architecture.
The Bigger Picture
This wasn’t about building a product that scales to millions of users. It was about understanding how systems scale conceptually.
I learned:
- How independent services stay decoupled
- How to handle failure in distributed contexts
- How observability prevents guessing
- How clean architecture makes systems adaptable
What’s Next?
The codebase is on GitHub. Feel free to explore: https://github.com/kareemhamed001/ecommerce-microservices
This project is educational. But the lessons are real. And they’ve already shaped how I design systems today.
For aspiring backend engineers: Don’t just learn frameworks. Learn how systems are built. The framework is a detail. Architecture is everything.
Tags: #Microservices #SystemDesign #DistributedSystems #BackendEngineering #Golang #gRPC #CleanArchitecture #SoftwareArchitecture

